
授業に潜入! おもしろ学問
市村賢士郎 国際高等教育院附属データ科学イノベーション教育研究センター 特定助教
ある集団の現象を数量的に把握し、その数値を分析して傾向や規則性などを読みとる統計学。実験結果や科学的な主張の根拠に用いられる、科学研究に重要な学問だ。コンピュータの発展で膨大で多様なデータを迅速に処理できるようになり、統計学は企業のマーケティング調査などにも重用されている。
世論調査やテレビ番組の視聴率、商品の利用者アンケートなど、私たちはさまざまなデータにかこまれ、その情報に依存して暮らしている。数字で表され、客観的だと思われがちな統計学だが、決して「絶対的」ではない。統計には「不安定」な部分もあることを忘れてはいけない。
授業に潜入!
これまでの授業では、t検定や分散分析、相関係数の有意性検定など、さまざまな統計的検定(検定)の方法を学んできました。検定結果は、確率や数値で表されますから、「客観的である」と思われています。しかし、分析に使う基準や条件には、人間が選択して決める恣意的な部分が多くあります。
恣意的な部分の一例として、有意水準の設定があります。有意水準は、帰無仮説を棄却するかどうかを決める基準の確率αのことです。帰無仮説とは、2つのデータには「差がない・関係がない」ことを意味する仮説です。検定の結果、p値がαよりも低い値になれば、帰無仮説を棄却し、「有意差あり」と判断します。αは5パーセントに設定されることが多いですが、この数字にはなんの根拠もなく、慣習的なものです。10パーセントにすれば、当然、有意差は出やすくなりますし、1パーセントにすれば、有意差は出づらくなります。
極端なことをいえば、求める結果が出るように有意水準を設定することも可能なのです。そのほか、分析方法の選択や、調査対象の人数や属性の設定なども、分析者が恣意的に選ぶことができます。だからこそ、恣意的に選んでしまわないように注意が必要です。研究の目的と照らしながら、データを収集する前にはしっかりと、有意水準や分析方法などの設定を決めておくのが望ましい態度です。
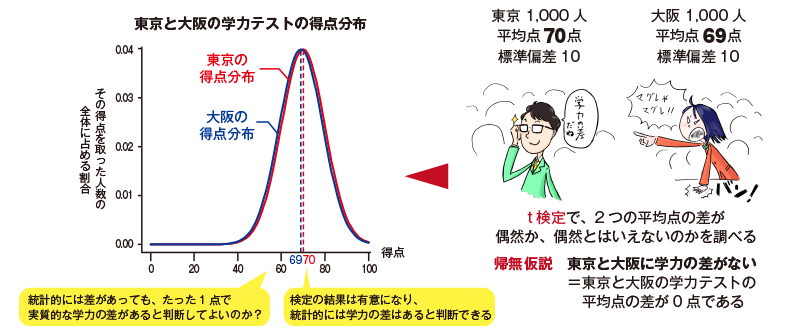
統計的検定における「有意な差」は、「実質的な差」ではないことにも注意です。たとえば、東京と大阪の高校の生徒を各1000人集め、学力テストを実施し、東京の平均点は70点、大阪の高校は69点、標準偏差がそれぞれ10だったとします。❶ このとき、有意水準を5パーセントに設定したt検定の結果は有意になり、「東京と大阪の学力には有意差がある」と結果上はいえます。しかし、実際の点数の差はたった1点です。検定で有意だからといって、この1点の差から、東京と大阪では学力に実質的な差があるといえるのか。この点は慎重に考えなければなりません。
検定ではまず、帰無仮説を立てます。さきほどの学力テストを例にすると、「東京と大阪には、学力の差がない」という帰無仮説が立てられます。しかし、東京と大阪のすべての高校生に学力テストを実施したとき、「すべての学生の点数に差がない(=平均点の差がぴったりゼロになる)」ことはほぼ起こりえないでしょう。ですから、人数が増えれば増えるほど、「差がない」という帰無仮説は棄却され、「有意になる」のはある意味必然。こうしたことからも、統計的に有意だからといって、実質的な差があるとは必ずしもいえません。
❶ 2つのグループの平均値の差を調べる
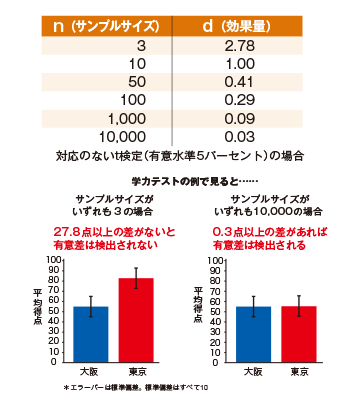
具体的な数値でこれを説明しましょう。❷ 表のnはサンプルサイズ、dは効果量を表します。サンプルサイズが3のときに、5パーセント水準で有意差が検出されるときの効果量は2.78以上。つまり、2つの平均値の差がかなり大きくなければ有意になりません。一方、サンプルサイズが1万になると、効果量が0.03倍という、ごくわずかな差でも有意になるのです。
❷ サンプルサイズと有意差

一方で、統計的に有意な差が認められないからといって、実質的な差がないとも、必ずしもいえないのです。
あるコインが「表の出やすいイカサマコインかどうか」を調べようと、コインを10回、100回、1000回投げるという試行をそれぞれ実施し、どの試行も6割の割合で、表が出たとします。一方でしかけのない通常のコインを使ってそれぞれの試行を100回ずつ繰り返すというシミュレーションをした結果が❸です。
イカサマコインでなくても、10回投げて表が6回出ることはわりと起こりうることだと、みなさんも想像できるでしょう。通常のコインで6割が表になる確率は約20.5パーセント。仮にイカサマコインであったとしても、6割が表だったという結果からは通常のコインなのか、イカサマコインなのかを判断することはできません。しかし、通常のコインを100回投げたとき、6割が表になる確率は5パーセント未満です。通常のコインを1000回投げたとき、6割が表の確率はほぼ0パーセントです。したがってコインを投げる回数が多い(サンプルサイズが大きい)ほど、より自信を持って「イカサマコインだ」と判断できるのです。このように、実際にはイカサマコインを使っていて、実質的な差があったとしても、サンプルサイズが小さいときには有意差は検出しにくくなるので、注意が必要です。
サンプルサイズが大きすぎると、実質的に意味のない差まで検出しやすくなり、サンプルサイズが少ないと、実際に差があるのに検定では有意になりにくいことは、これまでにお話ししました。実際の研究では、「検定力分析」という手法を使って、これらのバランスの取れたサンプルサイズをあらかじめ決定することが望ましいのです。
❸ コイントスの試行実験
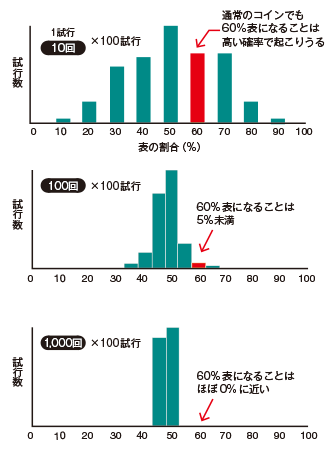
左のグラフは、しかけのない通常のコインを投げたときのシミュレーション結果。上からそれぞれ、「10回投げる」、「100回投げる」、「1,000回投げる」ことを1試行とし、それを100試行繰り返した。10回投げて6回が面になることは多いが、100回投げて60回が表になるのはごくわずか。さらに、1,000回投げて600回が表になることはほぼ0試行。サンプルサイズが増えるほど、表の割合が60%だったという結果からより確実に「通常のコインか、イカサマコインか」を判断できる。

統計的検定は絶対的なものではないことは理解できましたか。理由の1つは、結論を導き出すプロセスに恣意的な面が多くあるからですね。検定によってデータの解釈の主観性を抑えられることは確かですが、ある現象を一般化することはできません。
検定の結果はあくまでも抽出したサンプルからの推定です。1回の検定結果から、「人間はこうだ」など、母集団全体の傾向に明確な結論をくだすことはできませんし、結果を個々の事例にあてはめるのはもってのほかです。
極端な例では、「男性は女性よりも平均身長が有意に高い」という結果が得られたからといって、「男性であるAくんは、女性であるBさんよりも身長が高い」とはかぎりません。「収入が高いほど幸福感が高い」という相関関係が有意でも、「Dさんよりも、収入の高いCさんはより幸福」とはかぎらないのです。❹
❹ 極端な解釈

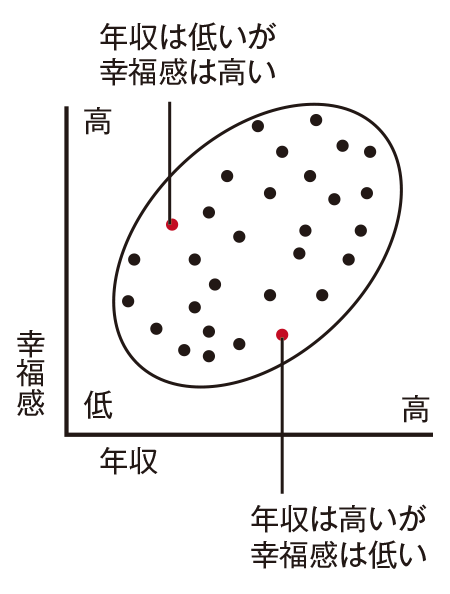
統計の結果では、「収入が高いほど幸福感は高いという相関関係が有意」と出たとしても、実際の個別の事例を見れば、結果とは異なる事例が存在することがわかる。
すこしでも一般化された結論に近づきたいときは、同じ条件で追試験(追試)を繰り返すことが重要です。ちなみに、ある研究では、論文として発表された心理学研究の39パーセントしか追試ができなかったという結果が出ています。心理学は人間を扱いますから、個人差が大きく、まったく同じ条件での追試は難しいのですが、専門家の厳しい査読を受けて発表された論文ですら、その61パーセントは追試しても同じ結果にならない。私も心理学者ですから耳の痛い事実ですが、1回の検定結果から明確な結論をくだすことはできないことを示す例です。
また、一度の実験で、考えられるすべての要因やその影響を検討することはほぼ不可能ですから、すこしずつ条件を変えた研究を積み重ねることが重要です。なにも自分1人で行なう必要はありません。すでに発表された先行研究に条件を追加して分析したり、自分の研究にほかの人が要因を追加したりすることで、より一般化された結論に近づきます。「巨人の肩の上に立つ」という言葉がありますが、研究は過去の先行研究の積み重ねで成り立っています。
さて、実社会に目を転じてみましょう。私たちの身のまわりには不適切なグラフが溢れています。提示されたグラフをうのみにせず、批判的にながめる視点を身につけ、惑わされないでほしいものです。
これはインフルエンザの感染者数を示したグラフです。❺ 昨年と一昨年とで、流行しているウイルスの型が違うことを示そうとしているのですが、左右のグラフの縦軸の目盛が違っています。これではグラフから受ける印象がずいぶん変わってしまいます。
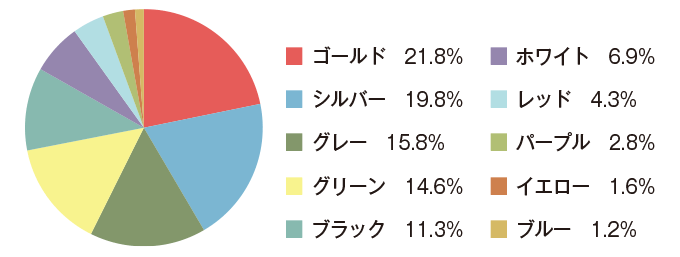
これは、ある携帯電話について、どの色がどのくらい売れているのかを示したグラフです。❻ 「ゴールド」がグラフでは赤色、「シルバー」が青色で示されています。グラフの目的は、一目でわかるようにデータを伝えること。グラフの数値は合っていても、直感的にわかりづらいグラフは適切でありません。
❺ おかしなグラフの例1
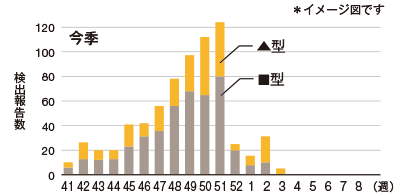
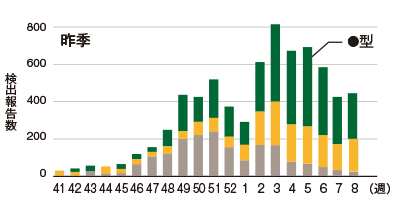
「今季は●型は流行していない」ということが言いたいのに、縦軸に注視しなければ、「今季も昨季と同じくらいの数の人が罹患しているんだね」という印象を受けてしまう。
❻ おかしなグラフの例2
問題は配色だけにあらず。グラフを見ずとも、パーセンテージの数字で内容は把握できるので、わざわざグラフにする意味はない。

統計の結果が不適切に使われて、判断を誤る例も溢れています。たとえば、「晴れの国」といわれる岡山県に出張した3日間、ずっと雨だったからといって、「岡山県が〈晴れの国〉というのは誤りだ」と、少数事例をもとに結論を導いてはいけません。
あるいは、「がん患者のほとんどが米をよく食べている。だから、米は発がん性の高い食品だ」。これは当然、誤りです。日本人なら、がん患者でなくてもお米をよく食べます。この関係を発信したいなら、がん患者とそうでない人のお米の摂取量別に群を分け、それぞれのがん発生率を比較すべきです。
一面的に因果を解釈することも問題です。「東京大学の学生は他大学の学生に比べ、幼少期にピアノを習っていた割合が高い」というデータがあります。だからといって、「勉強のできる子に育てるには、ピアノを習わせるのが有効だ」とは判断できません。「学力の高い人はピアノに関心を持ちやすい」という逆の因果関係があるかもしれませんし、親が教育熱心な傾向や、高収入な家庭が多く、塾やピアノ教室に通わせる余裕があるという可能性もあります。
主張の根拠が示されていれば、問題点は見抜きやすいのですが、それをあいまいにして、「お米は発がん性が高い」という主張だけを耳にした場合はどうでしょう。もっと悪質な場合には、主張に沿うように、データやグラフを都合よくゆがめて提示された場合はどうでしょう。
このようなケースは身のまわりに溢れています。安易に主張にのらず、信ぴょう性を吟味することが重要です。もちろん、データを発信する側に立つときも、自分の主張ありきでデータ収集や分析をしたり、データをゆがめたりすることは言語道断。
「統計は絶対ではない」。これを頭の片隅にいつも置きながら、統計と向きあってください。統計を学ぶコツは、「習うより慣れろ」。授業や読書だけでは、なかなか身につきません。データを使って分析しながら、統計的なセンスを磨いてください。
いちむら・けんしろう
1989年、石川県に生まれる。2018年、京都大学大学院教育学研究科博士後期課程を修了。2018年4月から現職。京都大学大学院教育学研究科特定助教を兼任。2019年9月から、同志社大学文化情報学部嘱託講師も務める。
センター長に聞く
データ科学を学ぶ意義
山本章博 教授
国際高等教育院附属データ科学イノベーション教育研究センター

やまもと・あきひろ
1960年、京都府に生まれる。京都大学理学部卒業、九州大学大学院総合理工学研究科博士後期課程修了。北海道大学工学部助教授などをへて、2003年から京都大学大学院情報学研究科教授。2018年からは同大学国際高等教育院附属データ科学イノベーション教育研究センター長を併任。
ICTが浸透した現代は、収集されるデータが大規模になっている。「統計学」をはじめとして、データを扱う手法を対象とする学問領域は、計算機に携わる情報学の分野を巻き込みながら、その存在感を増している。しかし、日本では、データを分析し、分析結果を適切に利用できる人材がまだまだ不足している。「かつて京都大学の全学共通科目で統計学を学べるのは、『数理統計学』と『社会統計学A・B』の3つだけでした。理系学部や経済学、心理学などの学部・学科では、統計学に関わる専門科目が用意されていますが、いまやデータ分析は専門家だけのものではありません」。
こうした現状をふまえ、京都大学に在籍する情報・統計・数理の専門家が集い、2017年に「データ科学イノベーション教育研究センター」を設置。統計学の全学共通科目を増やし、データサイエンスの〈いろは〉を伝えるべく活動している。
「データサイエンス(データ科学)」とは、「収集したデータを数理的な手法で分析し、導きだした結論をもとに将来を推測する学問」のこと。たとえば、キャッシュレスでの買い物は自身の購買データを企業に渡すことと同義。レジをとおして集約されたデータは、仕入れ量の決定や、客の嗜好を分析した新商品の開発などに活用される。「国勢調査などの大規模な方法を取らずとも、大量のデータが簡単に集まる時代です。企業に限らず、法律・政策、健康・医療、災害対策など、多様な分野でデータ活用のニーズは高まるはず。大学生のうちに、IT社会で活躍するスキルや武器を身につけてください」。
テレビや雑誌、広告では、データ集計の結果のグラフや表を参照したキャッチ・コピーに頻繁に出くわす。データを恣意的に利用して、事実を捻じ曲げているものも。「データ分析や統計的推測の〈いろは〉を学んでおけば、データに翻弄されることもありません。研究活動や業務に関係せずとも、データリテラシーは必要です。現代はもはや、データと無縁では生きられない時代なのです」。

