2011年5月12日

河原教授
衆議院の新しい会議録作成システムにおいて、河原達也 学術情報メディアセンター教授らの研究開発による自動音声認識技術が導入されました。約1年間の試行を経て、このたび本格的に運用されることになりました。
研究の背景とシステムの位置づけ
明治23(1890)年に我が国に議会が設立されて以来百年以上にわたり、会議録の作成は手書き速記によって行われてきました。今世紀になって衆参両院において速記者の新規採用・養成が停止され、新たな会議録作成方法が模索されました。様々な検討をふまえて、衆議院において音声認識技術を用いたシステムが採用されました。世界的にみても、国会の審議音声を直接認識するシステムは初めての事例です。
このシステムでは、原則すべての本会議・委員会の審議において、発言者のマイクから収録される音声を自動音声認識により書き起こし、会議録の草稿を生成します(図1参照)。なお、音声認識には一定の誤りが不可避な上、話し言葉の発言を忠実に書き起こしても、会議録になりません(図2参照)ので、速記者・校閲者の役割がなくなるわけではありません。
音声認識技術はこの十年余りの間に進歩を遂げて、最近では携帯電話を用いた情報検索や自動翻訳などのサービスなどに導入されています。ただし、国会の委員会審議のような自発性の高い、人間どうしの自然な話し言葉音声を高い精度で認識できるものはありませんでした。
研究の技術的ポイント
河原教授らは、まず衆議院の審議音声と忠実な書き起こし(実際の発言内容)からなるデータベース(=コーパス)を構築し、会議録の文章との違いを統計的に分析し、モデル化を行いました。その結果、「えー」や「ですね」などの冗長語の削除を中心に、約13%の単語で違いが見られました(図2参照)。次に、この統計モデルに基づいて、大量の会議録テキスト(過去10年以上の分;約2億単語)から、実際の発言内容を予測するモデル(=言語モデル)を構築しました。さらに、これと音声を照合することで、大量の審議音声(約500時間分)から音声パターンのモデル(=音響モデル)を構築しました(図3参照)。これらは半自動的に追加学習・更新が可能ですので、今後総選挙や内閣改造があっても話者集合の変化を反映し、持続的に性能を改善していくことができます。
システムの評価と今後の展望
この音声認識技術は、一般競争入札を経て新会議録作成システムの開発を担当したNTT(NTT東日本、NTT研究所など)のシステムに組み込まれる形で導入されました(本学産官学連携本部を通じてライセンス供与)。
昨年度の試行において性能評価を行ったところ、会議録と照合した音声認識結果の文字正解率は89%に達していました。これを、速記者が専用エディタで修正・編集することにより会議録原稿を作成するシステムの有用性が検証され、本格的な運用となりました。
会議録作成以外の今後の展開としては、講演や講義などを対象とした字幕付与への取り組みを行っていく予定です。
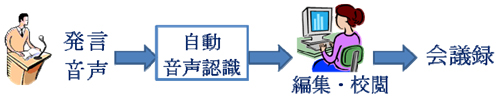
- 図1 システムの概要
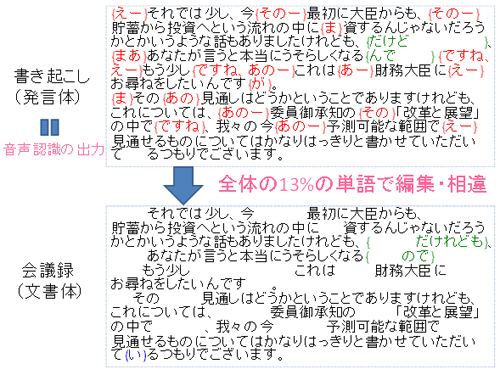
- 図2 書き起こし(発言体)と会議録(文書体)の相違の例
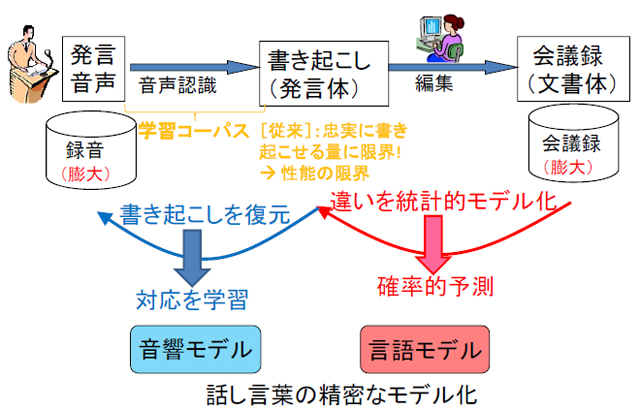
- 図3 本システムにおける音声認識技術の概要
この研究開発は、科学技術振興機構(JST)の戦略的創造研究推進事業(CREST)や、総務省の戦略的情報通信研究開発推進制度(SCOPE)などの国の競争的研究資金制度の支援を受けて行われました。
- 朝日新聞(5月13日 33面)、京都新聞(5月13日 23面)、産経新聞(5月13日 22面)、日刊工業新聞(5月13日 23面)、日本経済新聞(5月13日 38面)、毎日新聞(5月15日 23面)および読売新聞(5月30日 30面)に掲載されました。