本田直樹 生命科学研究科准教授、山口正一朗 情報学研究科修士課程学生(現・株式会社Preferred Networks)、石井信 同教授らの研究グループは、動物の行動データから報酬に基づく行動戦略を明らかにする機械学習法を考案しました。さらに、森郁恵 名古屋大学教授らと共同で、この手法を線虫の行動へと応用することで、その有効性を示しました。本手法によって、従来の行動が制限された行動実験系から開放され、より自然な状況において自由に振る舞う動物の行動戦略の研究が進むことが期待されます。
本研究成果は、2018年5月15日に米国の学術誌「PLoS Computational Biology」に掲載されました。
研究者からのコメント
ヒトや動物は、さまざまな状況に対してそれぞれ価値付けを行い、より価値の高い状況を目指す戦略を取っていると考えられます。今回私たちは、動物の行動データからその裏に潜む戦略を解読する計算論的手法を提案しました。この手法を用いることで、動物が何に価値を置いて行動しているのかを定量化することに成功しました。今後、この手法によって明らかにされる行動戦略と神経活動データを比較することで、行動戦略を司る神経メカニズムの解明に寄与することを期待しています。
概要
私たちヒトや動物は、より多くの報酬を得るため、状況に応じた「行動戦略」を持って生きています。報酬には食べ物やお金など実態の伴うものだけでなく、間接的にそれらに結びつくものも含まれているため、自由に行動している動物を単に観察しているだけでは、「動物が何を報酬として意思決定を行い、行動しているのか?」を知ることは困難でした。
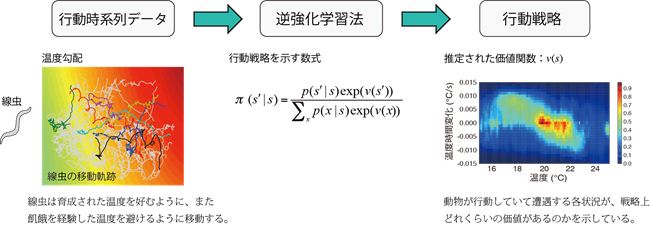
そこで私たちは、動物の行動時系列データから報酬に基づく行動戦略を明らかにする機械学習法(逆強化学習法)を提案しました。逆強化学習法の応用先として、シンプルなモデル動物である線虫C. elegansの温度走性行動に注目しました。線虫を温度勾配においてトラッキングすることで、行動時系列データを取得し、そして逆強化学習法により、線虫にとって何が報酬となっているのかを推定しました。
その結果、餌が十分ある状態で育った線虫は、「絶対温度」および「温度の時間微分」に応じて報酬を感じていることが明らかとなりました。この報酬に基づく戦略は一つは効率的に成育温度に向かうモード、もう一つは同じ温度の等温線に沿って移動するモードから構成されていました。さらに、推定された報酬を用いて、線虫行動をコンピュータでシミュレーションしたところ、線虫の温度走性行動が再現され、逆強化学習法の妥当性が示されました。
詳しい研究内容について
書誌情報
【DOI】 https://doi.org/10.1371/journal.pcbi.1006122
【KURENAIアクセスURL】 http://hdl.handle.net/2433/231173
Shoichiro Yamaguchi, Honda Naoki , Muneki Ikeda, Yuki Tsukada, Shunji Nakano, Ikue Mori, Shin Ishii (2018). Identification of animal behavioral strategies by inverse reinforcement learning. PLOS Computational Biology, 14(5), e1006122.



