
Prof. Kawahara
Since the Japanese Parliament (Diet) was founded in 1890, verbatim records had been made by manual shorthand over a hundred years. However, early in this century, the government terminated recruiting stenographers, and investigated alternative methods. The House of Representatives has chosen the Automatic Speech Recognition (ASR) technology for the new system, which has been developed by Prof. Tatsuya Kawahara’s group in Academic Center for Computing and Media Studies, Kyoto University. It is the first officially-deployed system in the world that automatically transcribes meeting speech in Parliament.
The new system handles all plenary sessions and committee meetings. Speech is captured by the stand microphones in meeting rooms. The speaker-independent ASR system generates an initial draft, which is corrected by reporters. There are still a certain amount of errors by the system as well as disfluencies and colloquial expressions, which are to be corrected, thus, reporters still play an important role.
Speech recognition technologies have made a significant progress in the past decade, leading to services such as voice search and speech translation by smart phones. However, it was still very difficult to accurately transcribe meeting speech given in committee meetings in Parliament, which are spontaneous, interactive, and often excited.
Prof. Kawahara and his colleagues first built a corpus of Parliamentary meetings, which consists of faithful transcripts of utterances aligned with official records, and they investigated the differences between them.
Although there are differences by 13% in words, majority of them are simple edits such as deletion of fillers and correction of a word. These can be computationally modeled by a statistical framework. This leads to an innovative approach for semi-automated corpus generation and ASR model training. By applying the statistical model to a huge scale of the past Parliamentary meeting records (200M words in text over 10 years), a precise language model that is to predict meeting speech is generated. Moreover, by referring to the audio data of each utterance, an acoustic model that memorizes the sound pattern for each phoneme is constructed. As these models can be updated in a semi-automated manner, they will evolve in time, reflecting the change of Members of Parliament (MPs) and topics discussed.
The ASR technology of the acoustic and language models has been integrated into the software engine of NTT Corporation, which made a successful bid for the entire system. (It was licensed via Office of Society-Academia Collaboration for Innovation.)
In the evaluations conducted in the last fiscal year, the accuracy defined by the character correctness compared against the official record reached 89%. The system is confirmed to be usable, together with the post-editor used by reporters to correct errors and clean transcripts. Thus, it is now in official operation.
Ongoing extensions of the technology include automatic captioning of lectures and assisting hearing-impaired students in universities.
This research and development has been sponsored by several national research funds including CREST (Core Research for Evolutional Science & Technology) program of JST (Japan Science and Technology Agency) and SCOPE (Strategic Information and Communications R&D Promotion Programme) of Ministry of Internal Affairs and Communications.
Prof. Kawahara will give a talk on this system in the Intersteno Parliamentary Reporters' Section (IPRS) meeting held in Paris on July 14, 2011.
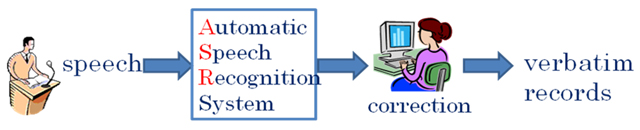
Fig.1: Overview of the system
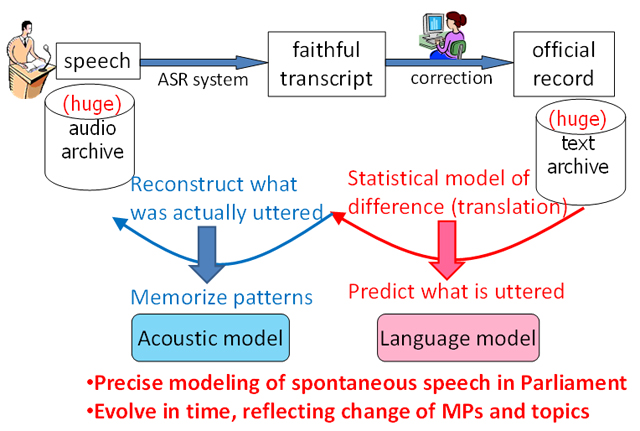
Fig.2: Overview of the speech recognition technology